本篇博客写于 2022-07-18,现在从我的旧博客搬运过来。当时还没有 ChatGPT,所以翻译的不太好,也无法保证没有错误,请见谅,原地址:https://blog.kitlau.dev/posts/how-is-data-stored-in-sql-database/
本篇博客技术相关内容翻译自 pragimtech 的:How is data stored in sql database,本文中大部分图片与代码出自该文章。
翻译水平有限,见谅。
0. 前言
作为开发者,数据库相关的知识十分重要,特别是当你想要排除故障并修复性能不好的 SQL 查询时。理解以下这些术语是非常重要的,特别是当你正在进行 Sql Server 性能调优相关的操作时。
- Data pages(数据页)
- Root node(根节点)
- Leaf nodes(叶节点)
- B-tree(B 树)
- Clustered index structure(聚集索引结构)
1. 数据是在物理上是如何存储在 SQL Server 中的?
表中的数据在逻辑上以行和列的格式存储,但在物理上,它以 Data pages(数据页)的形式存储。
数据页是 SQL Server 中数据存储的基本单位,每个数据页的大小为 8KB。当我们将任何数据插入到 SQL Server 数据库表中时,它将该数据保存到一系列 8KB 的数据页中。
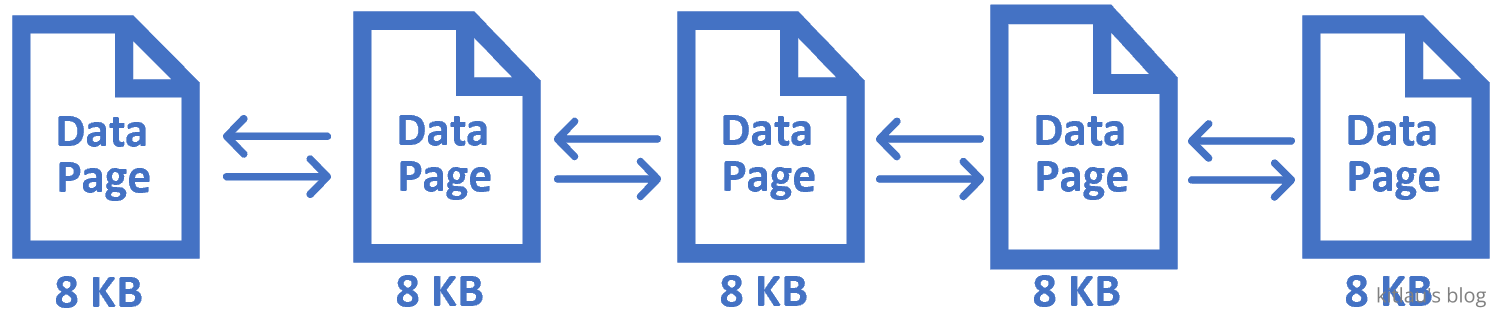 |
|---|
| 图 1 - 一系列 8KB 的数据页 |
2. SQL Server 中的数据存储在一个树状结构中
SQL Server 中的表数据实际上存储在一个类似树的结构中。让我们通过一个简单的例子来理解这一点。考虑下面的 Employees 表:
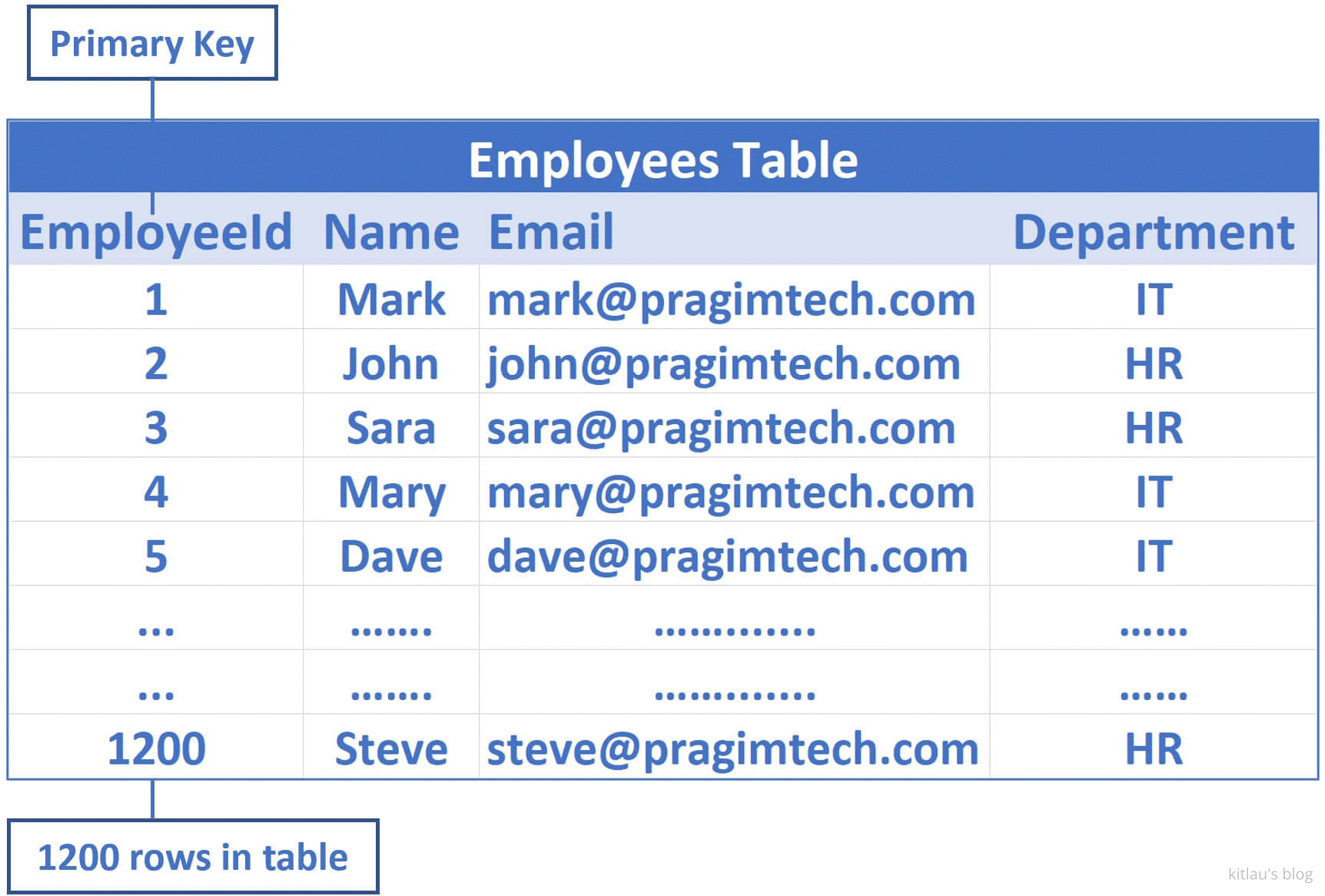 |
|---|
| 图 2 - Employees 表 |
EmployeeId是主键列;- 因此,默认情况下,将在
EmployeeId列上创建一个聚集索引; - 这意味着物理存储在数据库中的数据按
EmployeeId列排序。
看过我翻译的上一篇文章 【译】SQL 索引是如何工作的 的朋友应该已经猜的八九不离十了。
3. 数据实际存储在哪里
它存储在一系列数据页中,这些数据页的树形结构如下所示。
这种树状结构称为:
- B-Tree(B 树);
- index B-Tree(索引 B 树);
- Clustered index structure(聚集索引结构)。
这 3 个名字的意思是一样的。
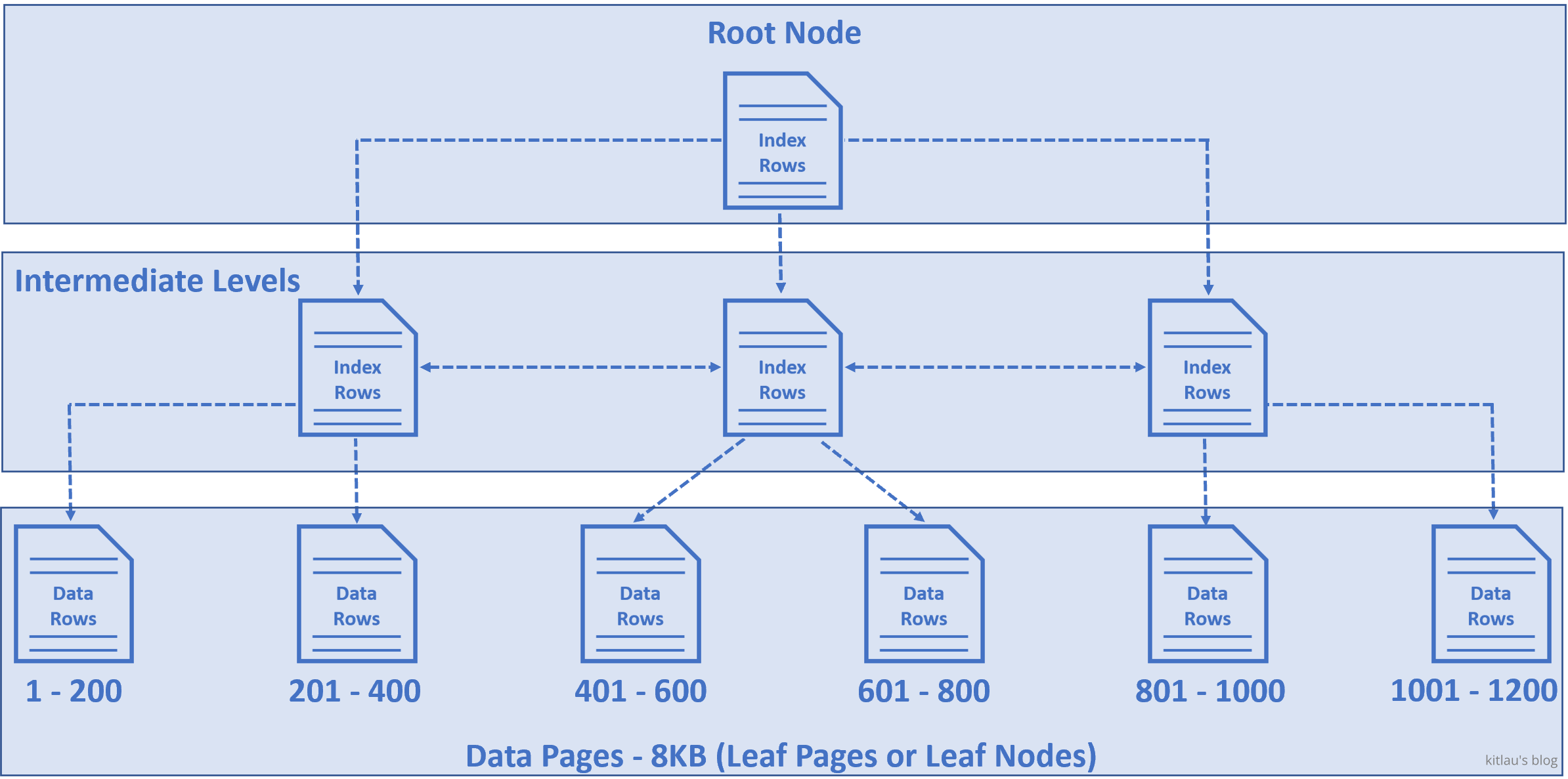 |
|---|
| 图 3 - 聚集索引结构 |
这实际就是我翻译的上一篇文章的聚集索引结构。
- 在树底部的节点称为数据页或树的叶节点,正是这些叶节点包含我们的表数据。(我们的表数据物理上就是存储在这些叶节点内)
- 每个数据页的大小为 8KB。这意味着每个数据页中存储的行数实际上取决于每行的大小。本例假设一行只有 40B,一个数据页就可以存储 200 行数据。
- 在我们的例子中,假设在这个 Employees 表中有 1200 行,我们假设每个数据页中有 200 行,但实际上,根据实际的行大小,我们可能会有更多的行或更少的行,但在这个例子中,我们假设每个数据页有 200 行。
- 记住,重要的一点是:这些数据页中的行是按
EmployeeId列排序的,因为EmployeeId是我们表的主键,因此是聚集键。 - 因此,在第一个数据页中,我们有 1 到 200 行,在第二个是 201 到 400 行,在第三个是 401 到 600 行,以此类推。
- 位于树顶部的节点称为根节点。
- 根节点和叶节点之间的节点称为 intermediate levels(中间层)。
- 可以有很多个中间层。在我们的示例中,我们只有 1200 行,为了使示例简单,我只有 1 个中间层,但实际上,中间层的数量取决于底层数据库表中的行数。
- 根节点和中间层节点包含 index rows(索引行),而叶节点(即树底部的节点)包含实际的数据行。
- 每个索引行包含一个键(在本例中为
EmployeeId)和一个指向 B 树中的中间层节点或叶节点中的数据行的指针。 - 所以重点是:这个树状结构有一系列的指针,可以帮助数据库引擎快速找到数据。
4. SQL Server 如何通过 ID 找到一个数据行
这部分在我翻译的上一篇文章中已经包含了(【译】SQL 索引是如何工作的 - SQL Server 是如何通过 ID 查到数据行的?),这里不再翻译。
本文以清晰的逻辑框架和示例辅助,系统性地解析了SQL Server中数据的物理存储机制,其核心价值在于将抽象的数据库结构可视化,为开发者提供了性能调优的理论依据。文章的优点主要体现在以下方面:
结构化呈现与示例结合
通过分章节讲解数据页、B树结构、聚集索引等核心概念,并配以图示(如图1-3)和Employees表的实例,有效降低了复杂概念的理解门槛。例如,将1200行数据拆解为6个8KB数据页的假设,直观展示了行数与页数的对应关系,同时强调了主键排序对物理存储的影响,这种量化举例对初学者尤为友好。
知识链的构建
通过引用前作《SQL索引是如何工作的》,形成“索引结构—数据存储—查询优化”的知识闭环,既避免了内容重复,又为读者提供了进一步学习的路径。这种串联式写作方式有助于读者建立系统性认知。
核心理念的准确性
文章准确传达了SQL Server物理存储的核心逻辑:
这些内容均符合SQL Server的底层实现原理,尤其对叶节点存储实际数据行的描述,精准揭示了聚集索引与非聚集索引的根本区别。
可改进空间
细节补充建议
行数 = 8096 / (列总大小 + 23),增强示例的严谨性。逻辑延伸方向
翻译优化建议
总结与延伸建议
本文作为SQL物理存储机制的入门指南,已完整覆盖基础知识点,建议后续可沿以下方向深化:
作者对技术细节的严谨态度和坦诚的翻译说明值得肯定,期待后续内容在保持通俗性的同时,逐步引入更高阶的实践技巧,形成从理论到落地的完整学习路径。
这篇关于SQL数据库数据存储机制的博客写得非常详细且易于理解。作者通过清晰的结构和具体的例子,成功地解释了SQL Server中数据如何物理存储以及索引的作用。
文章的优点在于其逻辑性:从介绍关键术语到逐步拆解树状存储结构,再到通过实际示例进行说明,层层递进,帮助读者构建全面的理解。图表的使用也恰到好处,视觉上辅助理解复杂的概念,比如B-Tree的结构和数据页的分布。
核心理念强调了理解数据库物理存储的重要性,这对于进行有效的查询优化和故障排除至关重要。作者通过Employees表的例子,展示了聚集索引如何影响数据行的排列顺序,这对性能调优有直接指导意义。
建议进一步探讨的内容可能包括:不同类型的索引(如非聚集索引)及其对查询性能的影响,以及在高并发场景下的存储机制优化策略。此外,加入一些实际应用案例或常见问题解答,可以增强文章的实用价值和读者的兴趣。
总体而言,这是一篇内容丰富、结构清晰的基础知识介绍,适合作为学习SQL Server内部工作机制的参考材料。对于数据库新手来说,这篇文章提供了坚实的理解基础;而对于有经验的开发者,它也起到了很好的复习和强化作用。
首先,我想对你的文章表示赞赏。你的文章清晰地解释了 SQL 数据库如何存储数据,包括了数据页、根节点、叶节点、B树和聚集索引结构等重要概念。这些内容对于理解数据库性能优化等高级概念非常有帮助。
你以一个实例来解释这些概念,使得这些抽象的概念更加直观易懂。图文并茂,使得读者能够更好地理解和记住这些概念。同时,你也解释了 SQL Server 如何通过 ID 找到一个数据行,这对于理解 SQL 查询的工作原理非常有帮助。
然而,我觉得你的文章还有一些可以改进的地方。首先,你在文章中提到了一些术语,例如数据页、根节点、叶节点、B树和聚集索引结构,但并没有对这些术语进行详细的解释。虽然你通过一个实例解释了这些概念,但我认为如果能在提到这些术语时,对它们进行详细的解释,会使得读者更好地理解这些概念。其次,你的文章主要关注了 SQL Server,但并没有提到其他的 SQL 数据库系统,例如 MySQL 或 PostgreSQL。我认为如果能够对比不同的 SQL 数据库系统,会使得文章更加丰富。
总的来说,你的文章是一篇优秀的技术文章,我期待你的下一篇文章。