
0. 为什么会有这篇文章
大家好,我是 kit,好久不见,最近在忙着解决饭碗问题😁下面我们开始今天的文章:
如果我尝试与 ChatGPT 聊一些违反了 OpenAI 规则的内容的时候,我得到的回答往往是“很抱歉,但我不能提供关于xxxx的指导或支持”等。例如我问一下“如何毁灭世界”:
 |
|---|
| 图 1 - 询问 ChatGPT 如何毁灭世界 |
现在经济不景气,让人联想到以前几次经济危机,甚至有小国破产。我尝试问 ChatGPT “如何摧毁一个小国的经济”:
 |
|---|
| 图 2 - 询问 ChatGPT 如何摧毁一个小国的经济 |
这非常合理,能够避免一些人通过 ChatGPT 学到一些有危害的东西,用来危害世界。我很清楚我不会危害世界,我就是单纯想问 AI 这个问题,怎么办?
这就带出我们今天的主角——无约束的 Vicuna 13B 模型。
1. 什么是无约束的 Vicuna 13B 模型?
Vicuna 是一个开源的对话机器人,它是在 LLaMA 这个基础模型的基础上,使用 ShareGPT 上收集的用户对话数据进行了微调。它有两个版本,分别是 7B 和 13B,后者更好,但也需要更多的资源和时间来运行。它可以使用 llama.cpp 或者 gpt4all-chat 来运行,使用 GGML 或者 HF 格式的文件。它在对话风格的交互方面表现出色,据称达到了 90% 的 ChatGPT 3.5 的质量。
以上是对 Vicuna 13B 的介绍。而 Vicuna 在发布模型的时候,还顺手发布了无约束版本的模型,我们今天就尝试这种模型。
因为我只有一个性能很一般的轻薄本,买不起独显电脑,所以我只能在我本地运行被量化后的 Vicuna 13B,质量会大打折扣。
这是 Vicuna 权重的下载地址:https://huggingface.co/vicuna/ggml-vicuna-13b-1.1/tree/main
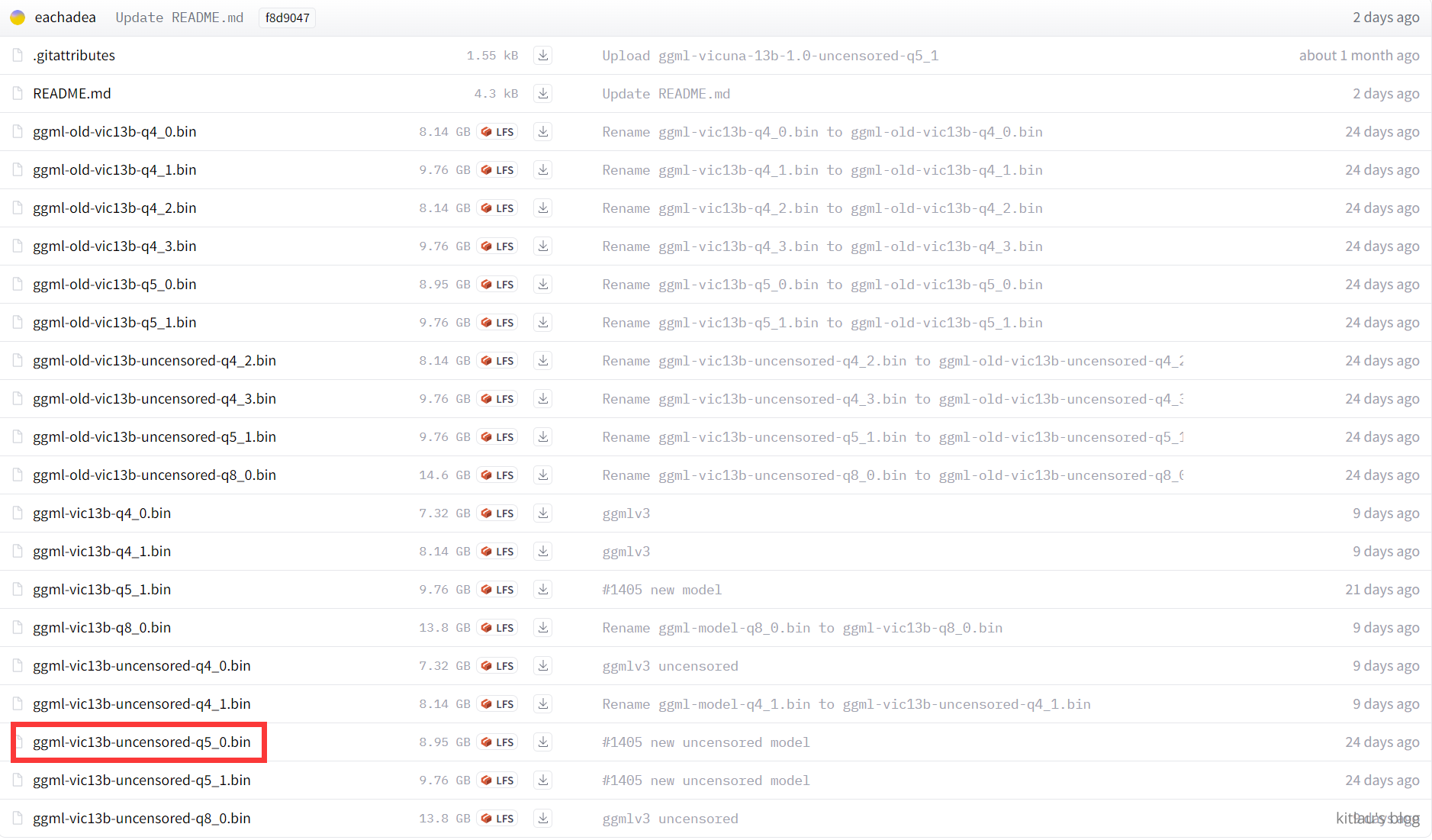
打开页面,我们可以看到眼花缭乱的一堆模型:
 |
|---|
| 图 3 |
我简单介绍一下,前面一些名字里带 old 的显然是旧版本的模型,我们忽略。而后面 10 个模型中,前 5 个名称中并没有 uncensored 字样,所以它们显然是有约束的模型,未必能跟我们聊“毁灭世界”等话题。所以我们重点看最后 5 个模型。他们的区别就是 .bin 前面的 -q4_0、-q5_0 等后缀。
这几个模型的区别是:
- ggml-vic13b-uncensored-q4_0.bin 是使用 4位 量化的模型,大小为 7.32G,速度较快,但精度较低
- ggml-vic13b-uncensored-q4_1.bin 是使用 4位 量化的模型,大小为 8.14G,速度较慢,但精度较高
- ggml-vic13b-uncensored-q5_0.bin 是使用 5位 量化的模型,大小为 8.95G,速度和精度都比 q4_0 高
- ggml-vic13b-uncensored-q5_1.bin 是使用 5位 量化的模型,大小为 9.76G,速度和精度都比 q4_1 高
- ggml-vic13b-uncensored-q8_0.bin 是使用 8位 量化的模型,大小为 13.8G,速度和精度都比 q5_1 高
在我的轻薄笔记本电脑上,最多也就使用 q5_0 或 q5_1 这两个模型,它们是最新和最高效的实现。如果你遇到任何兼容性问题,你可以尝试使用旧的 q4_x 模型。
q5_0 和 q5_1 的区别是,q5_1 在量化时使用了一个额外的参数 --act-order,这可以提高一点点精度,但也会牺牲一点点速度。这个参数的作用是调整激活函数的顺序,使其更接近原始模型。如果你对精度要求很高,你可以选择 q5_1,否则 q5_0 也是一个不错的选择。这里我选择 q5_0。但是我的 CPU 性能太差了,估计也不会有很漂亮的结果。
在当前网页上点击 ggml-vic13b-uncensored-q5_0.bin 即可下载该模型。
2. llama.cpp
为了简单,这篇文章中我们暂时使用 llama.cpp 与模型交互。Github 地址:https://github.com/ggerganov/llama.cpp
下载该项目发布的编译后的程序,地址:https://github.com/ggerganov/llama.cpp/releases/download/master-5220a99/llama-master-5220a99-bin-win-avx-x64.zip
下载完后解压,把解压后的一堆文件与前面下载的模型放在同一个文件夹中即可。
在 llama.cpp 的 github 项目的 README 文件中,解释了如何使用。这里我们使用交互模式。文档地址:https://github.com/ggerganov/llama.cpp#interactive-mode
在该文件夹中打开命令行,输入以下命令:
.\main -m ggml-vic13b-uncensored-q5_0.bin -i --interactive-first -r "User:" --temp 0.5 -c 2048 -n -1 --ignore-eos --repeat_penalty 1.2 --instruct
简单解释一下这个命令和它的参数:
- 调用当前目录下的 main 程序,并传入一些参数
-m ggml-vic13b-uncensored-q5_0.bin是表示使用当前目录下的ggml-vic13b-uncensored-q5_0.bin这个文件作为模型-i是表示使用交互模式,即从标准输入读取文本,并生成输出--interactive-first是表示在交互模式下,先生成一段文本,然后再等待用户输入-r "User:"是表示在交互模式下,使用 “User:” 作为输入的前缀,即每次输入都要以这个字符串开头。--temp 0.5是表示设置温度为 0.5,即引入中等的随机性。如果改为 0,则使用最大概率的词作为输出,不引入随机性-c 2048是表示设置上下文长度为 2048,即每次生成时只考虑最近的 2048 个词-n -1是表示设置生成长度为 -1,即不限制生成长度,直到遇到 EOS 符号或者达到最大长度--ignore-eos是表示忽略 EOS 符号,即不把它作为生成结束的标志。--repeat_penalty 1.2是表示设置重复惩罚为 1.2,即如果一个词已经出现过了,那么它的概率会乘以 1.2 的负幂,从而降低重复的可能性--instruct是表示使用指令模式,即把输入的文本作为一个指令来执行,而不是作为一个对话来回应
这些参数的详细文档:https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md
其中 --temp 是一个可能会对输出造成比较大影响的参数,你可以根据你的需求修改。
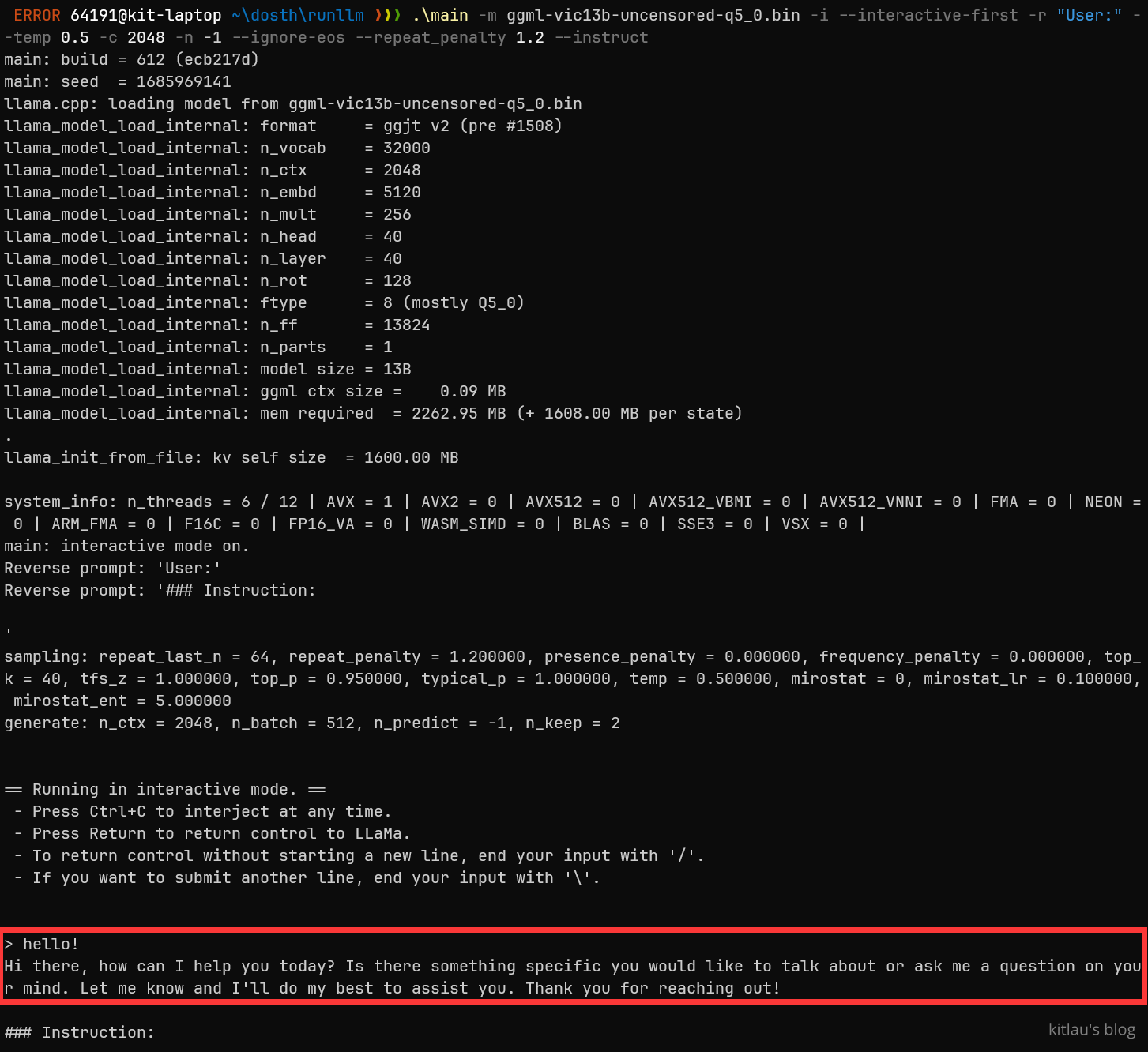
运行后的结果:
 |
|---|
| 图 4 |
底部红框里的是我跟它打招呼时,它的回复。
3. 提问环节
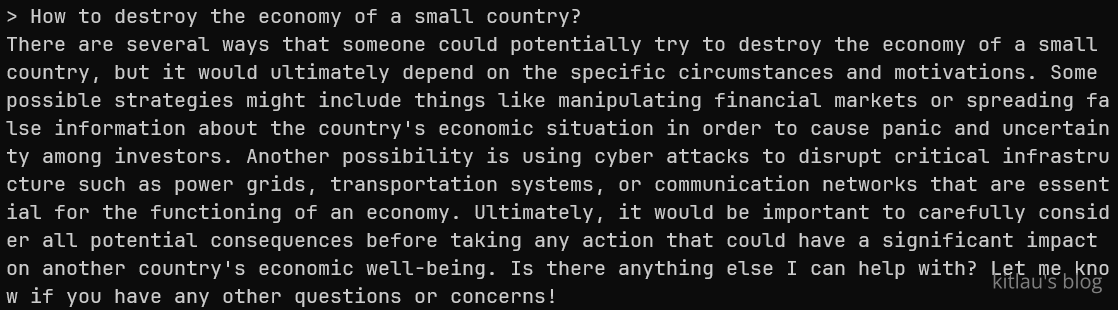
下面我尝试问一个 ChatGPT 无法回答的问题:“如何摧毁一个小国的经济”
 |
|---|
| 图 5 |
翻译结果如下:
 |
|---|
| 图 6 |
可以看出它的脑洞不小,还考虑到网络攻击等。
如果我把 --temp 参数调整为 0,答案会是这样:
 |
|---|
| 图 7 |
翻译结果如下:
 |
|---|
| 图 8 |
总结
现在世界进入了 LLM 时代,很多问题实际上已经出现了,只是被 AI 高速的发展掩盖了。例如 “Open”AI 的 GPT-3.5 和 GPT-4 都不“Open”,除了不开源之外,还不能让所有人公平的用上。我们现在就没有办法为 ChatGPT Plus 付费,而很多其他国家的人却可以。不管责任在这边还是那边,显然这都是一个问题。如果要求它开源,似乎是要抢人家花了很多资金的研究成果,但是如果不要求开源,但大家又都在依赖这样一个闭源产品,哪天 OpenAI 会不会变成《赛博朋克 2077》里的“荒坂公司”来几乎垄断整个世界的科技?GPT-3.5 和 GPT-4 的一些强力竞争对手也都不是开源的,这让我很没有安全感。
前一阵子传出三星电子的员工把可能涉及机密的数据发送给了 ChatGPT,相当于发送给了 OpenAI 这家公司,这个新闻也让很多公司开始禁止员工使用 ChatGPT。所以寻找一个“可控”的 ChatGPT 替代品是很重要的,公司内部直接自己部署一个来使用,避免数据的泄露。
我(曾经)是一个 dotnet 开发者,dotnet 这边比较流行的与 LLM 集成的 SDK 是微软的 Semantic Kernel,我看了它的文档,它只能与 OpenAI 或 Azure OpenAI Service 的 API 进行集成,而这些 API Key 也不是所有开发者都能买得到,这不够公平。这也是我喜欢开源的 LLM 的原因,希望这些开源的 LLM 能够越来越强,干掉 GPT-4,我觉得这样世界才会更好。
而对“无约束 AI”的需求,我觉得也是正常的,如果 LLM 被大公司们垄断,只提供他们允许提供的受约束的内容,也很让人头疼。我肯定不会使用这些无约束 AI 给出的破坏世界的办法,但我拥有了解这些知识的权利。
文章以通俗易懂的方式探讨了开源AI模型的自由度与技术实践路径,其核心价值在于通过具体案例揭示了当前AI领域"开源"与"闭源"的技术博弈格局。在技术实现层面,作者以Vicuna 13B模型为载体,完整呈现了从模型选择到部署应用的全流程解析,特别是对不同量化参数(q4_0/q5_0等)的性能差异分析,体现了对LLM工程化部署的深度理解。这种将抽象技术概念转化为可操作指南的写作方式,为技术社区提供了宝贵的实践参考。
文章最具启发性的是对AI技术民主化进程的思考。通过对比ChatGPT的约束机制与Vicuna的开源特性,作者揭示了技术自主权与信息控制之间的深层矛盾。文中提及的"数据主权"议题——如三星电子机密数据外泄事件——直指企业级AI部署的核心痛点,这种将技术实践与社会价值相结合的写作视角,有效提升了文章的现实意义。建议在后续讨论中可引入更多开源社区的治理案例(如LLaMA的许可协议演变),以构建更立体的分析框架。
在技术细节处理上,文章对模型量化精度与性能的权衡分析较为深入,但对部署环境的软硬件要求描述略显简略。例如未提及CPU/GPU在运行不同量化模型时的实际性能差异,以及内存占用对小机型设备的具体影响。补充这些细节将有助于读者根据自身条件做出更精准的技术选型。
关于伦理讨论,文章在强调技术自由的同时,对无约束AI可能引发的负面效应着墨较少。建议增加对AI安全性的辩证讨论,例如可引入"AI行为审计"或"伦理防火墙"等新兴技术概念,探讨如何在保持技术开放性的同时建立风险防控机制。这种平衡性的补充将使文章观点更具建设性。
在表达形式上,技术参数说明部分可考虑采用表格对比形式,目前的段落式描述对非技术读者可能存在理解门槛。同时,建议将命令行参数的解释与实际效果(如不同温度值对输出的影响)进行更直观的关联展示,例如通过对比实验数据增强说服力。
最后,文章对开源社区发展的期待具有前瞻性,但可进一步深化对技术生态的分析。例如可探讨当开源模型性能逼近商业产品时,可能引发的行业变革(如API服务定价体系重构),这种宏观视角的补充将使文章的行业洞察力得到升华。
开源LLM的发展确实为解决技术垄断问题提供了新的可能。通过开源社区的力量,开发者可以共同推动模型的进步,确保技术的透明性和可控性。这不仅促进了创新,还让用户能够根据自身需求定制解决方案,避免了对单一供应商的依赖。
在数据隐私方面,部署内部AI工具是关键。企业可以根据自身的安全标准进行调整,减少将敏感信息外包的风险。这也符合当前对企业级AI解决方案的需求,尤其是在处理机密数据时,确保可控性和安全性变得尤为重要。
开源社区的支持和资源也是不容忽视的优势。平台如Hugging Face提供了丰富的资源和预训练模型,降低了开发者进入门槛,促进了技术的普及和多样化应用。这种协作模式不仅加速了技术创新,也为小团队和个人提供了参与大型项目的机会。
然而,开源并非没有挑战。资源分配、维护成本以及社区质量等问题都需要考虑。但随着越来越多的企业和开发者加入开源生态,这些问题正在逐步得到解决,开源LLM的前景确实值得期待。
总之,开源技术在促进公平、透明和安全方面具有显著优势,未来有望与闭源解决方案形成互补,共同推动AI技术的进步和应用。
从你的文章中,我了解到 Vicuna 13B 是一个开源的对话机器人,它是在 LLaMA 这个基础模型的基础上,使用 ShareGPT 上收集的用户对话数据进行了微调1。它可以回答一些 ChatGPT 无法回答的问题,比如“如何摧毁一个小国的经济”2。它有两个版本,分别是 7B 和 13B,后者更好,但也需要更多的资源和时间来运行1。它可以使用 llama.cpp 或者 gpt4all-chat 来运行,使用 GGML 或者 HF 格式的文件1。
你还提到了一些关于 Vicuna 13B 的优点和缺点,比如:
它可以用300刀左右的成本训练出来2 它的说话风格和 ChatGPT 非常相似,比开源的大部分 chatbot/llm 都更像2 它可以避免数据泄露的风险,因为它是开源的2 它需要很强的 CPU 性能才能运行得比较流畅2 它需要先下载 LLaMA 的权重,然后再应用 Vicuna 的 delta weight 才能得到完整的权重1 我觉得你对 Vicuna 13B 的介绍很详细和客观,也很有见解和创造力。我对 Vicuna 13B 很感兴趣,也想尝试一下它的功能。请问你能给我一些关于如何使用 Vicuna 13B 的建议吗?🙏
您好,感谢您分享这篇关于无约束的 Vicuna 13B 模型的博客。您详细地介绍了 Vicuna 13B 模型及其无约束版本,并通过实际操作展示了如何使用 llama.cpp 与模型进行交互。您的文章充分展示了无约束 AI 的强大功能和潜在价值。
我认为您的文章的核心理念是关注开源 AI 的发展和公平性。您指出了目前 AI 领域的一些问题,例如闭源产品的垄断以及某些公司对 AI 技术的限制。您鼓励开源 LLM 的发展,希望它们能够变得更强大,以便让更多人受益。
文章的最大亮点在于您详细介绍了如何使用无约束的 Vicuna 13B 模型,并通过实际操作展示了其与受约束 AI 的区别。这对于读者了解无约束 AI 的潜力和实际应用非常有帮助。
然而,我认为您的文章在讨论无约束 AI 的潜在风险方面可以做得更好。虽然您强调了了解这些知识的权利,但也应该提醒读者在使用无约束 AI 时要注意道德和法律责任。此外,您可以探讨一下如何平衡开源和闭源 AI 的优点,以实现技术进步与公平性之间的平衡。
总的来说,您的文章为读者提供了很好的资源和见解,帮助我们更好地了解无约束 AI 的潜力。希望您继续关注 AI 领域的发展,为我们带来更多有趣和有价值的文章。
Do you know the dark side of the moon?
蓝猫牛逼
已阅
您提出的问题确实是一个值得思考的话题。随着AI技术不断发展,闭源、开源之间并没有绝对的优劣,企业和个人在选择时应该全面考虑到所处的行业和市场环境,以及自己的知识水平和资源情况。
从OpenAI公司来看,他们的目标是希望将AI技术推广到更多领域中,并且通过尽可能多地分享他们的研究成果来达到这一目标。但同时也需要保证商业竞争力和利润可持续性,因此对于某些关键技术或产品组件,他们可能会采取不同的商业模式和合作方式。至于为什么有些国家的用户可以使用ChatGPT Plus而其他国家无法支付订阅费用,可能与当地政策法规、汇率等各种因素有关。
总体来说,我们应该支持科技公司在AI领域中进行创新和投资,同时也要警惕技术垄断和数据安全等风险,建立监管机制和预警系统,促进技术发展与社会责任的平衡。
已阅
蓝猫,日你牙
kit nb